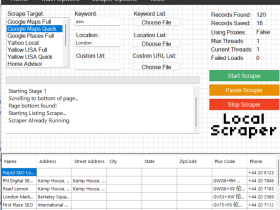
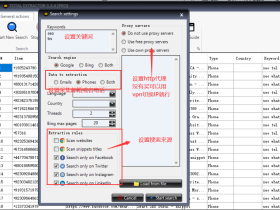
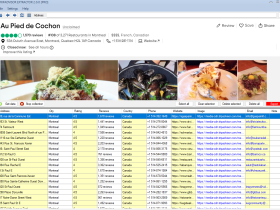
WebHarvy是一款可视化的网页数据抓取软件,可以自定义从任何网站 抓取文本、HTML、图像、URL 和电子邮件,并以各种格式保存抓取的数据。
官方网址:https://www.webharvy.com/index.html (可以免费试用)
售价:129美金每年
本站售价500元终身,绑定一台电脑使用。
文字教程:https://www.webharvy.com/docs/starting-configuration.html
视频教程:https://www.youtube.com/playlist?list=PL5JXukqcKuSWiDqx7MpZlL93fPLn0o8NU
软件主界面及演示:
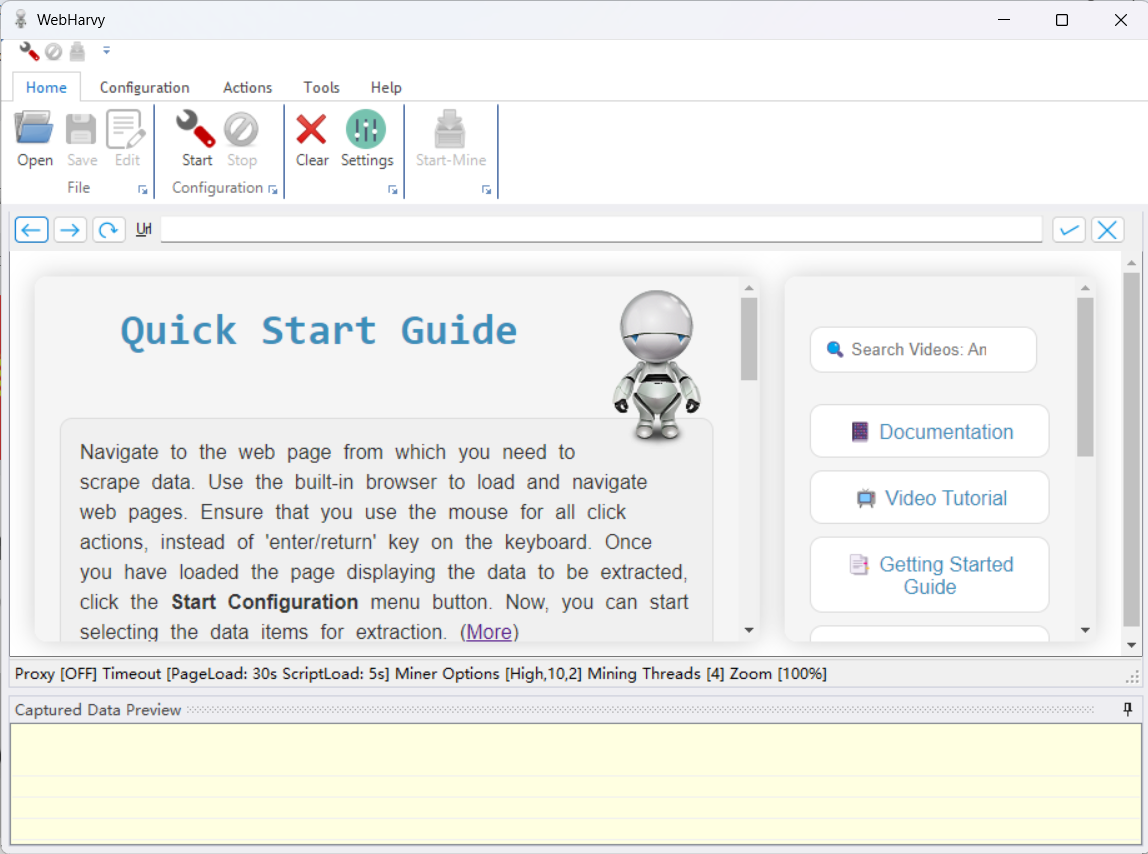
WebHarvy 功能
非常易于使用。WebHarvy 可以从任何网站抓取数据,处理登录、表单提交、导航、分页、类别和关键字。支持代理和计划抓取。
轻松网页抓取
借助 WebHarvy 的点击界面,网页抓取变得轻而易举。抓取数据无需编码或脚本。使用 WebHarvy 的内置浏览器,您可以加载网站、浏览页面,只需单击即可选择要抓取的数据。
智能模式检测
WebHarvy 可以智能识别网页中出现的数据模式。从网页中抓取项目列表或表格(姓名、地址、电子邮件、价格等)无需额外步骤。如果数据重复,WebHarvy 将自动抓取。
保存到文件或数据库
抓取的数据可以以多种格式保存。最新版本的 WebHarvy 允许您将数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。此外,您还可以将数据直接导出到 SQL 数据库(MySQL、SQL Server、Oracle 等)。
处理分页
WebHarvy 可以轻松抓取跨多个页面的数据,例如产品列表或搜索结果。它支持各种分页方法,包括无限滚动、加载更多按钮、页码链接、URL 列表等。
提交关键字
通过自动在搜索表单中提交关键字列表来抓取数据。您可以向多个文本输入字段提交无限数量的关键字,从所有关键字组合的搜索结果中抓取数据。
保障隐私
为了匿名抓取数据并避免被网络服务器阻止,WebHarvy 提供了使用代理服务器或 VPN 的选项。您可以选择通过单个代理服务器或轮换代理列表访问目标网站。
类别抓取
WebHarvy 可让您从指向网站上类似页面或列表的链接列表中抓取数据。此功能可让您使用单一配置抓取网站内的类别和子类别。
正则表达式
正则表达式 (RegEx) 可应用于网页的文本或 HTML 源以抓取匹配部分。这种强大的技术为您提供了更大的灵活性和对数据选择的控制。
JavaScript 支持
在抓取数据之前,在浏览器中运行自定义 JavaScript 代码。此功能允许您与页面元素进行交互、修改 DOM 或触发页面上已实现的 JavaScript 函数。
图像抓取
可以下载图像或抓取图像 URL。WebHarvy 可以自动抓取电子商务网站产品详细信息页面中显示的多幅图像。